Vector Search: Semantic Discovery in E-commerce
Executive Summary
Lexical search—keyword matching—fails in high-stakes e-commerce because it cannot interpret intent, only syntax. Vector search replaces brittle term matching with semantic proximity, transforming product discovery into a continuous space of meaning, not a finite grid of catalog entries.
Introduction: The Collapse of the Keyword Paradigm
Keyword search works fine when someone types 'Nike Air Max 270 size 10.' But what about 'something elegant for a summer wedding'? That's where traditional search fails — and where vector search changes the game.
Vector search does not merely incrementally improve recall. It restructures the relationship between user and inventory. By embedding both products and queries into high-dimensional semantic spaces, we move beyond the logical constraints of keyword matching. Discovery becomes a proximity problem. Relevance becomes a distance metric. And the catalog becomes a topology of meaning rather than a flat list of SKUs.
This is not an optimization. This is a re-architecture.
The Technical Ontology of Vector Search
From Token Matching to Dense Embeddings
Legacy search systems operate on sparse vectors—inverted indexes where each dimension corresponds to a unique term. The absence of a word yields a zero. The presence yields a count. This model is computationally efficient but semantically blind. Synonyms are invisible. Context is ignored. Polysemy (same word, different meanings) introduces noise that cannot be filtered without explicit rules.
Vector search replaces this sparse representation with dense embeddings: continuous, low-dimensional vectors generated by transformer-based models (BERT, SBERT, or domain-fine-tuned alternatives). Each dimension encodes latent features—style, formality, material, use case—learned from co-occurrence patterns across massive corpora.
A “velvet blazer” and a “plush dinner jacket” may share zero lexical tokens. In embedding space, their cosine distance collapses toward zero.
The Geometry of Relevance
Once all catalog items and user queries map to vectors in the same latent space, relevance becomes a geometric operation. The standard metric is cosine similarity—the cosine of the angle between two vectors, ranging from 1 (identical direction, semantically identical) to -1 (opposite direction, antithetical).
In practice, a search query is embedded at inference time. The system then performs an approximate nearest neighbor (ANN) search over the product corpus. The top-k results are those with the smallest angular distance to the query vector.
This is not ranking by keyword frequency. This is ranking by semantic proximity. The difference is the difference between a librarian who only reads titles and one who understands literary theory.
| Feature | Lexical Search (Keyword) | Vector Search (Semantic) |
|---|---|---|
| Matching Logic | Exact string matching / Stemming | Mathematical distance in latent space |
| Intent Recognition | Zero (Syntax only) | High (Contextual understanding) |
| Synonym Handling | Manual mapping required | Intrinsic semantic clustering |
| Ranking Metric | Term frequency (TF-IDF/BM25) | Cosine similarity / Euclidean distance |
| Scalability | Degrades with long-tail queries | Flourishes with complex intent |
Architectural Implications for High-Stakes E-commerce
Latency as a First-Order Constraint
Luxury users do not wait. Their expectation is not patience but instantaneous precision. Vector search, naively implemented, is computationally expensive. A brute-force linear scan over millions of 768-dimensional vectors is O(n * d)—unacceptable at scale.
Production systems therefore rely on ANN indexes:
- ▸HNSW (Hierarchical Navigable Small World): Graph-based structure that partitions the vector space into navigable layers. Query complexity approaches O(log n).
- ▸IVF (Inverted File Index): Partitions vectors into clusters via k-means. Search occurs only within the nearest clusters.
- ▸HNSW + PQ (Product Quantization): Compresses vectors into smaller codes. Reduces memory by ~80% with marginal recall degradation.
For luxury catalogs (typically 10k–200k SKUs, not millions), HNSW without quantization is often optimal: sub-50ms latency at >95% recall.
The Cold Start Problem for New Inventory
Vector search models are trained offline. When a new product enters the catalog, it has no precomputed embedding. The architectural solution is a dual-path pipeline:
- ▸Batch embedding generation (nightly or hourly) for bulk updates.
- ▸Real-time inference via frozen model for new arrivals, with eventual consistency.
Critically, the frozen model must remain static between retraining cycles. Online learning in embedding spaces is an unsolved problem for production e-commerce—gradient drift introduces non-deterministic relevance.
Multi-Modal Vectors (Text + Image + Behavior)
The most sophisticated implementations do not stop at text. They fuse three distinct modalities into a single unified vector:
- ▸Text embeddings (product titles, descriptions, specs)
- ▸Image embeddings (via ResNet, ViT, or CLIP)
- ▸Behavioral embeddings (collaborative signals from past user interactions)
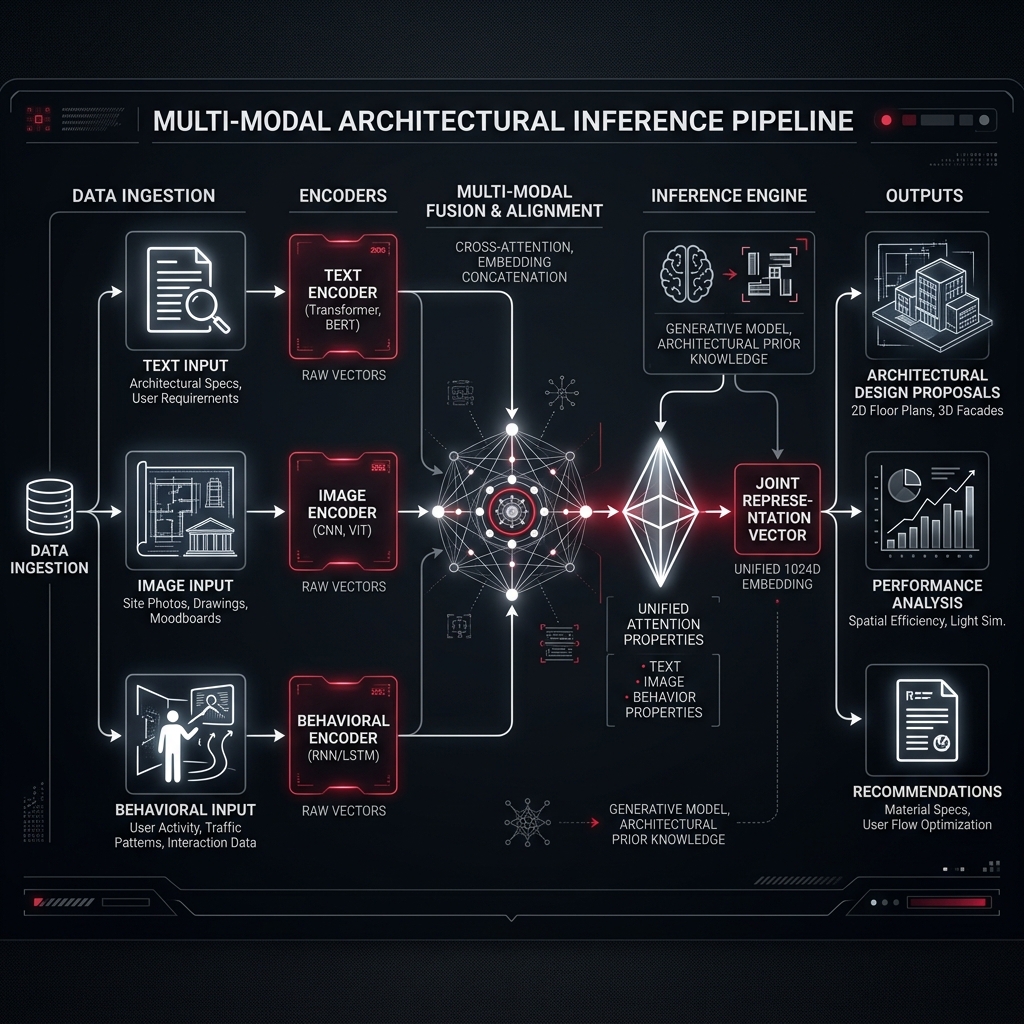
Fusion happens via weighted concatenation or learned attention. The result: a product vector that encodes not just what the product is, but how users relate to it. A black handbag from two different maisons may have similar text and image vectors but diverge sharply in behavioral space if one is favored by a high-LTV segment.
Business Metrics That Vector Search Actually Moves
Beyond Recall—The Luxury Metrics
Standard e-commerce celebrates recall@10 and MRR (Mean Reciprocal Rank). For luxury, these are necessary but insufficient. The true KPIs shift:
- ▸Semantic Serendipity Rate: Percentage of discovered products that share no lexical tokens with the original query but result in add-to-cart.
- ▸Zero-Results Rate Collapse: Lexical search systems generate 5–15% zero-result queries for long-tail luxury terms. Vector search reduces this to <0.5%.
- ▸Average Discovery Depth: Number of products viewed before first add-to-cart. Vector search typically reduces this by 30–40%.
The Margin-Aware Retrieval Layer
Standard vector search is margin-agnostic: it retrieves what is semantically close, regardless of profitability. For luxury agencies, this is unacceptable. The architectural pattern is two-stage retrieval:
- ▸First-stage (Semantic): Retrieve top-200 candidates via ANN.
- ▸Second-stage (Weighted): Re-rank candidates using a composite score:
Score = α * cosine_similarity(query, product) + β * (product_margin / max_margin) + γ * inventory_age_decayThis ensures that semantic relevance remains the primary signal, but commercial objectives bias the final ordering. The coefficients α, β, γ are optimized via bandit algorithms or offline A/B testing.
Implementation Architecture for Enterprise Luxury Brands
The Inference Pipeline
User Query → [Embedding Model (frozen)] → [ANN Index (HNSW)] → [Re-ranker] → [Top-K Results]
↑ ↑
[Pre-computed Product Vectors] ← [Offline Batch Job]Key engineering decisions:
- ▸Model choice: all-MiniLM-L6-v2 (384-dim, 80MB) for speed vs. intfloat/e5-large-v2 (1024-dim, 1.3GB) for recall. Luxury favors the latter.
- ▸Index freshness: Incremental HNSW updates require lock-free reads. Implement via double-buffering.
- ▸Fallback logic: When ANN recall confidence falls below threshold, degrade gracefully to hybrid lexical + vector search.
The Observability Layer
Vector search introduces non-determinism that lexical systems lack. The same query may return different results after model retraining. Observability must include:
- ▸Embedding drift monitoring: Track centroid movement of top-1000 products week-over-week.
- ▸Query-to-vector logging: Store query embeddings at inference time for retrospective recall analysis.
- ▸False positive audits: Randomly sample low-cosine-similarity results that converted, and high-similarity results that did not.
Semantic SEO for Vector-First Catalogs
How Vector Search Changes On-Page Optimization
Traditional SEO optimizes for keyword density, header structure, and exact-match domains. Vector search renders much of this obsolete. The embedding model does not care about keyword frequency; it cares about semantic coverage.
For a luxury product page, this means:
- ▸Descriptive breadth over keyword repetition: A single mention of “cashmere” is sufficient; surrounding context provides the semantic signal.
- ▸Structural semantics: HTML5 semantic elements (article, section) guide transformer attention.
- ▸Attribute normalization: Embeddings learn faster from structured data (Product, Material, Color) than from prose.
The Death of Exact Match Domains
Exact match domains (EMDs) once signaled relevance lexically. In vector space, the domain name is a token like any other—low weight relative to content. Luxury brands should allocate engineering effort to content depth and structured data, not keyword-stuffed URLs.
Vector search is a democratizing force: it rewards semantic substance over lexical trickery.
Anti-Patterns and Failure Modes
The Popularity Cascade
Vector search trained on user behavior can amplify existing popularity. A product that converts well becomes behaviorally similar to itself, creating a self-reinforcing loop that suppresses long-tail inventory. Mitigation:
- ▸Apply inverse popularity weighting to behavioral embeddings.
- ▸Implement exploration tokens: randomly inject 5% low-velocity products into top-100 results.
Semantic Collapse in Small Catalogs
For catalogs under 1,000 SKUs, the embedding space may not be sufficiently dense to separate distinct products. The solution is not to abandon vector search but to augment with synthetic negatives—generate plausible but non-existent product embeddings as contrastive anchors during training.
The Interpretability Gap
CTOs cannot explain why a vector search result appeared. Lexical systems offer transparent term matching. Vector search is a black box. The architectural mitigation:
- ▸Explainability via attention: For transformer-based embedders, extract token-level attention maps.
- ▸Nearest-neighbor visualization: For any result, show the three nearest lexical neighbors.
Conclusion: Precision Without Dogma
Vector search is not a panacea. It introduces latency, non-determinism, and interpretability challenges that lexical systems avoid. But for luxury e-commerce—where the user’s vocabulary often fails to capture their taste—the trade-off is not merely acceptable. It is imperative.
The brands that adopt vector search will not market it. Their users will never see a “powered by AI” badge. What they will experience is a catalog that understands them without being told. That is the silent conversion EVDOPES engineers: discovery so precise it feels like intuition, architected so rigorously it disappears into the background.
Precision is not about controlling every variable. It is about designing systems where the emergent behavior—semantic discovery—is exactly what the user needed, even when they could not name it.